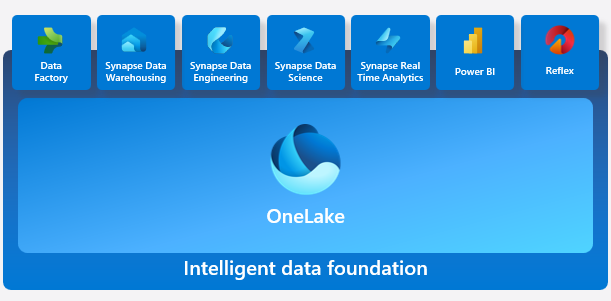
Microsoft has just announced a noteworthy development in the world of data analytics and AI: Microsoft Fabric. This new offering is more than just another product; it’s an integration of existing technologies into a unified platform, bringing together Azure Data Factory, Azure Synapse Analytics, and Power BI.
What particularly caught my attention is the potential this platform holds for data engineering workflows and AI applications.

Focus on Synapse Data Engineering
Synapse Data Engineering, one of the core workloads of Microsoft Fabric, stands out with several significant enhancements. The instant start with live pools feature is a massive quality of life improvement for developers. No more waiting around for resources to spin up before you can begin coding. In my view, this is a substantial time-saver that will streamline the data engineering process.
What’s more, the integration with VSCode is a huge plus. Many of us already use VSCode as our primary development environment, so this compatibility simplifies the transition and allows us to leverage the extensive ecosystem of VSCode extensions. Not to mention the added convenience of using GitHub Copilot for AI-powered coding assistance.
The Promise of OneLake
Another impressive feature is OneLake, the multi-cloud data lake that comes with Microsoft Fabric. It eliminates the need for data duplication and movement, as it allows data stored in Delta and Parquet tables to be used directly from PowerBI. This feature has immense potential to reduce both costs and time spent on data management.
OneLake also eliminates the issue of data silos, thanks to its unified storage system. It supports data sharing between users and applications with the help of “Shortcuts,” making data discovery and sharing easier than ever before.
Embracing Open Data Formats
Microsoft Fabric’s commitment to open data formats is noteworthy. Delta on top of Parquet files is treated as a native data format for all workloads, giving customers total flexibility. This means customers don’t need to maintain different copies of data for databases, data lakes, data warehousing, business intelligence, or real-time analytics. Instead, a single copy of the data in OneLake can be queried and analyzed by all workloads.
Looking Ahead
While these are the initial features that have grabbed my attention, there’s still a lot to unpack with Microsoft Fabric. I’m eager to explore further and uncover the full potential of this platform. I’m particularly keen to explore more about the AI features and how they can revolutionize data analytics.
In the coming weeks, I’ll be delving deeper into Microsoft Fabric, testing its capabilities, and sharing insights on how it can be leveraged effectively. So, stay tuned as we continue on this journey of discovery with Microsoft Fabric!
Leave a Reply
You must be logged in to post a comment.